आईआईटी रुड़की ने विकसित की संस्कृत भाव विश्लेषण पद्धति
आईआईटी रुड़की के शोधकर्ताओं ने संस्कृत टेक्स्ट के लिए भाव विश्लेषण पद्धति का विकास किया
oप्रस्तावित तकनीक संस्कृत टेक्स्ट में 92.83 प्रतिशत सटीक भाव वर्गीकरण करने में सफल
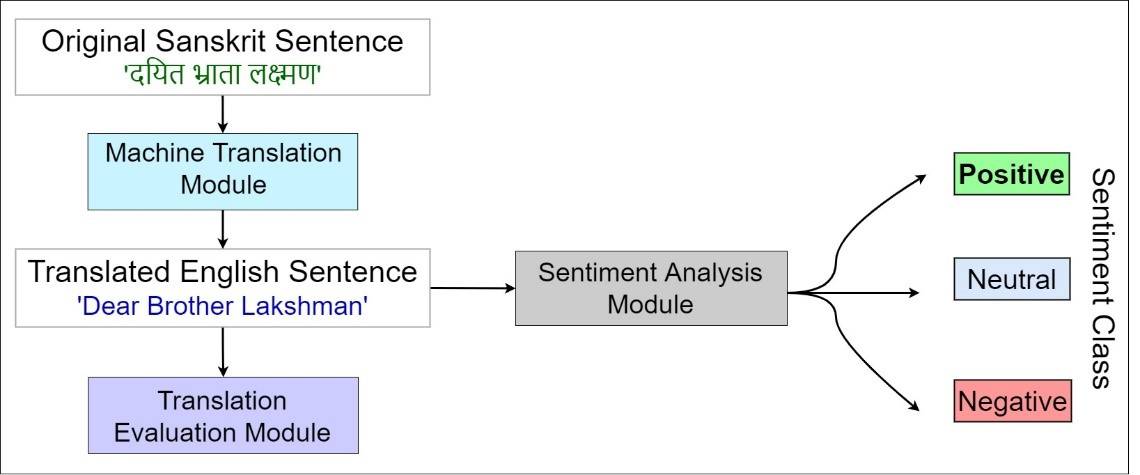
oभाव विश्लेषण मॉडल में मशीन ट्रांस्लेशन मॉडल, ट्रांस्लेशन इवैल्यूएशन मॉडल और भाव विश्लेषण मॉडल शामिल
oशोध के लिए डेटा वाल्मीकि रामायण वेबसाइट से लिए गए
रुड़की, 22 सितंबर 2022: भारतीय प्रौद्योगिकी संस्थान रुड़की (आईआईटी रुड़की) के शोधकर्ताओं ने संस्कृत टेक्स्ट के भाव विश्लेषण की एक कारगर विधि विकसित की है।
हालांकि संस्कृत दुनिया की सबसे प्राचीन भाषाओं में एक है लेकिन इसमें अब तक मशीनी अनुवाद और भाव विश्लेषण जैसे सहज भाषा प्रसंस्करण की खास कोशिश नहीं की गई है। ऐसे में आईआईटी रुड़की की तकनीक से 87.50 प्रतिशत सटीक मशीनी अनुवाद और 92.83 प्रतिशत सटीक भाव वर्गीकरण कर लेना बड़ी उपलब्धि है।
इसके बावजूद कि संस्कृत दुनिया की सबसे प्राचीन भाषाओं में एक है प्रचूर मात्रा में लेबल डेटा नहीं मिलने की वजह से मशीनी अनुवाद और भाव विश्लेषण जैसे सहज भाषा प्रसंस्करण कार्य बहुत कम हुआ है।
इस शोध में मशीनी अनुवाद, अनुवाद मूल्यांकन और भाव विश्लेषण मॉडल उपयोग करने का प्रस्ताव है। शोध करने वाली टीम में प्रोफेसर बालसुब्रमण्यम रमन, कम्प्युटर विज्ञान और इंजीनियरिंग विभाग और उनके पीएच.डी. छात्र श्री पुनीत कुमार और गणित विभाग में एम.एससी. के छात्र श्री क्षितिज पठानिया शामिल हैं।
मशीनी अनुवाद की मदद से मूल स्रोत और लक्षित भाषा की परस्पर भाषाई मैपिंग की गई है। इस तरह प्राप्त अंग्रेजी अनुवाद काफी परिपक्व और सहज हैं और अंग्रेजी के मौलिक वाक्यों की तरह हैं। यह मॉडल एक प्रतिष्ठित पीयर-रिव्यू जर्नल एप्लाइड इंटेलिजेंस (डीओआई – Applied Intelligence (DOI – https://doi.org/10.1007/s10489-022-04046-6)में एक शोध पत्र के रूप में प्रकाशित किया गया है।
भाव विश्लेषण मॉडल के बारे में जानकारी देते हुए आईआईटी रुड़की में कम्प्युटर विज्ञान विभाग के प्रोफेसर बालासुब्रमण्यम रमन ने कहा, ‘‘हम ने अपने मॉडल को इस तरह ट्रेन किया है कि पॉजिटिव, न्यूट्रल या फिर निगेटिव रेंज़ में सेंटीमेंट स्कोर बताए। हमारा मॉडल स्टैटिसटिक्स, सहज भाषा प्रसंस्करण, और मशीन लर्निंग की मदद से 90 प्रतिशत से अधिक सटीक भाव निर्धारण करने में सक्षम है।
शोध के लिए डेटा वाल्मीकि रामायण वेबसाइट (https://www.valmiki.iitk.ac.in ) से लिए गए, जिसके विकास और मेंटेन करने का काम आईआईटी कानपुर के शोधकर्ताओं ने किया है। शोधकर्ताओं की आगामी योजना बेहतर वर्गीकरण के लिए संस्कृत के मॉर्फोलॉजिकल गुणों का लाभ लेना है जिसके लिए केवल ‘मूल शब्द’ संबंधित ‘प्रत्यय’ और ‘उपसर्ग’ के साथ उपयोग किए जाएंगे। यह आकलन करने की योजना भी है कि क्या अंग्रेजी में अनुवाद करते हुए संस्कृत के मॉर्फोलॉजिकल गुण सुरक्षित रखे जा सकते हैं। इसके अलावा शोधकर्ताओं की योजना ऐसा मॉडल बनाने की है जो शब्दों के संदर्भ कई भाषाओं में समझे और छोटे आयामों में शब्दों का समावेश करे।

